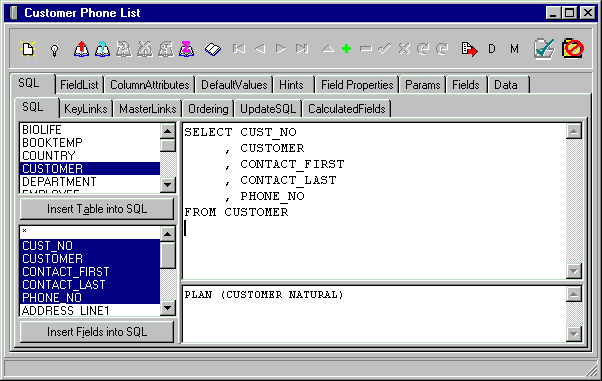
This tab is used to store forms to process SELECT statements selecting records into a buffered and scrollable dataset. It contains a list of names of the query forms that you have defined for the current layout. You can maintain as many query forms as you like.
When the Query Form is launched you will get this form to work with:
When the query is opened by clicking on the Open Book button the form changes to the Data tab and after resizing the columns a little this is what it looks like:
Because this is a buffered dataset there are a lot of things that can be done with it that can't be done with a cursor. Most significantly, it is possible to scroll to any of the records backwards and forwards by any increment. This makes for a flexible environment for the user to interact with when they can scroll around and take whatever operation they want on individual records. It is also possible to select groups of records, locate records, lookup record values, incremental search among records, and much more.
There are various optimizations and strategies that IBO allows you as a developer to configure in order to get the best performance and accuracy when working with a buffered dataset. Much of this will be covered in this tool's help file but more thoroughal coverage will be given in the regular IBO components help sections on the TIB_Query component and its base classes.
Setting up a Dataset
SQL.SQL Tab
As you can see, it is very simple to execute a query in IBO. SQL is the only required property in most all cases.
You get a helpful list of tables and fields for the database and the ability to have them added to the SQL statement for you by double clicking on them or selecting them and clicking the button to add them in. When the statement is prepared the PLAN for the statement is shown in the area below the SQL statement. Prepare it by clicking on the button with the light bulb on it.
SQL.KeyLinks Tab
IBO sometimes needs to have information in addition to the SQL property about the SELECT statement that is being executed in order to perform more advanced operations that the buffered dataset allows.
KeyRelation is the name of the main table of the SELECT in the case where there is a join between more than one table. This becomes the table that inserts, updates and deletes are performed on if a live dataset is requested. Unless you are using more than one table or view in a SELECT statement this property can be left blank.
KeyLinks is used in order to identify which columns of the SELECT statement can be used to uniquely identify each row of the dataset. If you don't know what they are or it isn't convenient to have that information ahead of time it is possible to set the KeyLinksAutoDefine property to true and have IBO attempt to figure out the KeyLinks for you automatically. If it cannot figure them out then they are left blank internally and an arbitrary integer is used to uniquely identify each record. But, in this case you become somewhat limited in what you can do with the dataset. It is best to supply the KeyLinks information if possible for performance reasons because you save the time it takes trying to figure it out for you.
If there is only one table in the FROM clause then you should only need to use the primary key column(s) for that one table. You can also use columns defined in a UNIQUE index too. It is only necessary to supply column references that will uniquely identify each row in the returned dataset.
If your query may have duplicate records in the output then you may need to use the DB_KEY feature of InterBase that defines a unique identifier for each record of a table.
If there is a join of multiple tables then you may need to use the DB_KEY or primary key columns of each table for its records.
DB_KEY is actually an internal (physical) pointer to where the record is stored in the database. Thus, this is guarenteed to be unique for each record even if its data is identical to another record in the table.
It is generally necessary that the KeyLinks columns be included in the output columns of the SELECT statement. The only exception being when the FetchWholeRows property is false.
The FetchWholeRows property is used to determine the buffering strategy that IBO should use to pull in the information for the dataset from the server. By default it is true and this is the normal mode of operation where it fetches in the records one at a time in whole. If this property is set to false then a brand new way of pulling in the information is used. This new approach is only appropriate for special situations. Do NOT use this setting if it is propable that all the rows of the dataset will be fetched in. It is much more efficient to use the FetchWholeRows as true when all or most of the records will be brought to the client.
The new buffering approach allows VERY large tables to be randomly browsed. Open a table with 100K rows and hit the LAST button. It flies like crazy to the end and gladly presents records from the end of the dataset. Getting back to the First record is instantaneous too! Do you need to wait again to get to the last record? Of course not! This is IBO under the hood! This is even feasible over a 28.8 dial-up connection!
How this works is IBO only fetches the keys that are necessary to define the records of the dataset. Then, it only fetched in the individual whole rows that it needs on demand. So, when you cann the Last method it grabs record keys until it gets to EOF and then it fetches in the individual rows at the end of the dataset. This leaves all the records inbetween the start and the end of the dataset on the server. Nor are they taking up memory in the client buffers since all IBO datasets use dynamic memory allocations with white-space suppressed.
The JoinLinks property may also be necessary if you are joining together tables in a dataset and not using the explicit syntax to do so. The rule of thumb on this one is if you are putting information in the WHERE clause that is actually part of the join's definition then it belongs in the JoinLinks property instead of the WHERE clause. At the time the statement is prepared and sent to the server IBO parses the JoinLinks information into the WHERE clause that is sent to the server.
The reason that this needs to be separated out is because there is a fair amount of parsing that goes on behind the scenes and IBO needs to distinguish between normal WHERE clause criteria and JOIN criteria. It is also a good idea to qualify the referenced columns with the name of their relation and a period.
Here is an example that illustrates a properly configured joined dataset using an IBO buffered query:
SQL:
SELECT *
FROM CUSTOMER, ORDERS, ITEMS
WHERE CUSTOMER.CUSTNO > :CUSTNO
FOR UPDATE
The PK columns from the customer and order tables are not needed in the KeyLinks property because there is a one-to-one relationship between ORDERS and CUSTOMERS and there is a one-to-many relationship between ITEMS and ORDERS which reduces it to a one-to-one as well. Thus, due to the inner join nature of this query the keys from the outer-most table are sufficient to uniquely identify all rows of the resulting dataset.
SQL.MasterLinks Tab
The GeneratorLinks property is used to provide generator values for fields when inserting records. It doesn't really have much to do with a master-detail relationship but this seemed like the best place to put this property.
Make entries to correlate columns with generators using this format:
[<table name>.]<field name>=<generator name>
The MasterLinks property is used to setup a master-detail relationship. Enter in columns with the Query as a detail to the Cursor which serves as the master when using IB_WISQL as a stand-alone utility. This means that the Cursor tab on the main page is the Master of the Master-Detail relationship whenever MasterLinks data is entered in the MasterLinks property of a Query form. Enter column correlation using the following format with a separate line item for each pair of fields that correlate together:
<detail table>.<detail field>=<master table>.<master field>
It is not necessary to add a parameter in the SQL property like the standard VCL requires. Use the MasterParamLinks property if you want to use the old TQuery method of parameter binding to tell which input parameters should be linked to the master dataset. Here is the format for its entries:
<detail param name>=[<master table>.]<master field>
Here's an example of a master-detail setup using the Mastapp database:
Cursor.SQL:
SELECT *
FROM CUSTOMER, ORDERS
WHERE CUSTOMER.CUSTNO=ORDERS.CUSTNO
Query.SQL:
SELECT *
FROM ITEMS
Query.KeyLinks:
ITEMS.ORDERNO
ITEMS.ITEMNO
Query.MasterLinks:
ITEMS.ORDERNO=ORDERS.ORDERNO
Prepare & open both datasets.
As you fetch records in the Cursor (master), look at the Data of the Query (detail).
There is a new batch of detail records for each master record selected.
If you really want to get brave go into search mode for the Cursor. Notice how the Query also went into search mode! You can enter search criteria in the detail records to determine records returned in the Master dataset!
Try this out and look in the SQL Monitor to see what SELECT statements are automatically being generated to accomplish this!
SQL.Ordering Tab The properties in this tab are designed to give you control over all ordering aspects of the dataset. It is possible to make settings that allow you to do incremental searching as well as have the grid title columns display an ordering indicator glyph as well as respond to a click in order to change the sort of the dataset.
The OrderingItems property is a list of entries that give ORDER BY clause criteria. Each entry is given a friendly name and then the actual columns for the ORDER BY are put after the equals sign. If a descending order is desired then a semicolon and the descending ORDER BY columns are entered. Here is the format:
<friendly ordering item name>=<ascending columns>[;<descending columns>]
You should enter in the exact text that you would enter in after the ORDER BY clause. So, for example, on the descending sort entry for a dual column sort you would write in:
Name=LASTNAME ASC, FIRSTNAME ASC; LASTNAME DESC, FIRSTNAME DESC
The OrderingItemNo property determines which ORDER BY criteria from the OrderingItems property is being used to sort the dataset. The way it works is if it is 0 then no entry is used from the list and the original ORDER BY clause that is entered into the SQL property is used. If it is 1 or more then it corresponds to the ascending item entries in the list and if it is negative then it corresponds with the descending item entries in the list.
The OrderingLinks property correlates a column to an OrderingItem entry. So, in our example above, because the LASTNAME column is the primary sort column for the Name ordering item it makes sense to correlate the LASTNAME column to the Name ordering entry. This is done simply by making the following entry in the OrderingLinks property:
LASTNAME=ITEM=1
This is assuming that the Name entry is the first one in the OrderingItems property. Here is the actual format of the OrderingLinks property:
[<table name>.]<column name>=ITEM=<ordering item no>[;POS=<char position>]
If we wanted to setup the incremental searching to only start taking action on an nth character then we can make a parameter entry for the POS parameter. This will make it so that when incremental searching it would only begin attempting to find a match after the nth character.
It also will cause horizontal dataset refinement to take place. But, there are likely going to be some changes taking place with this feature so that it is more transparent to the user. This will make it possible to do incremental searching on very large datasets as long as there is a persistant connection to the server. More on this in the future...
SQL.UpdateSQL Tab These properties are used to take control of how updates, inserts and deletes are performed for the dataset.
CachedUpdates is used to tell IBO to keep all the users changes in the buffer rather than immediately sending them to the server upon posting. This way, when you click on the CommitRetaining or Rollback buttons it will either Apply the updates and Commit or Rollback if it failed to apply all the updates or it will Cancel the updates if the Rollback button is clicked on.
PessimisticLocking is used in order to "touch" a record so that it will be held exclusively for the current transaction to furthur edit it and prevent all other transactions from editing it. When the dataset is put into dssEdit state it attempts to lock the record and if it succeeds then you go into dssEdit state. If it fails then an exception is raised and you remain in dssBrowse state.
PreparedEdits gives you a little more control over how the UPDATE statements are executed in order to handle how datasets post dssEdit state. If this is true then a single statement with all the columns is held prepared and waiting for an update to take place. All column values are plugged in and the UPDATE is performed. If this property is false then it will dynamically parse together a statement for each post of a dssEdit and send to the server a statement only updating the actual columns that changed.
ReadOnly causes the dataset to prevent all forms of data manipulation. It doesn't really provide any significant performance benefits if you are only selecting records. It may help avoid additional statements from being prepared in order to determine if CanModify is true or false, etc. To prevent inserts this must be set to true.
RequestLive tells that you want IBO to automatically put together the necessary UPDATE, INSERT and DELETE statements to make a dataset updatable.
SearchedDeletes and SearchedEdits tell that you want the WHERE clause to have the keys used to locate the record to be updated rather than using a CURSOR on the server for positioned updates.
The EditSQL, InsertSQL and DeleteSQL properties are used to define your own custom SQL statement to handle the posting of a dssEdit, dssInsert and dssDelete. It is possible to use a SQL statement of any kind where you use the parameter names to match the column names in the dataset. If you want to match up with the OLD column values then preface the parameter names in this property with OLD_<column name> and you will be able to get the value of the column before it was changed. It is also possible to use an EXECUTE PROCEDURE statement to handle the changes as well. Just name its input parameters based on the column values you want plugged into it. Be careful to make sure the column types and lengths are compatible.
Column Attributes
This property serves as a catch all for giving columns special information in order to create a desired behavior. There are more than a few defined and this will probably continue to grow over time.
Entries should be made in the following format:
[<table name>.]<field name>=<attribute>[ ; <attribute> … ]
There must only be a single entry for each column name where additional parameter settings are appended with a semicolon.
It may be useful to name your input parameters the same as fileds if they share the same property attributes. Otherwise, you will need to make an additional entry for each of them individually.
An attribute may also have parameters of its own.
The currently defined attributes are:
· 53 bit integer-based columns for high precision computational storage.
NOROUNDERR - Used with DECIMAL() column above 9 sig. digits.
CURR - Used for a DOUBLE PRECISION column and stores 4 decimal places.
COMP - Used for a DOUBLE PRECISION column and has no decimal places.
· Case insensitive searching on an alternate column. When in search mode QBE criteria may be entered into a field that is pointing to one column in the dataset that is case sensitive but you want the search to be case insensitive. Thus, by using this property you can tell it to apply the search criteria (which will be converted to uppercase) against an alternate column. Which column could be a trigger maintained copy of the original column with all of the data in uppercase. It is not necessary for the upper case column to be included in the SELECT statement's output columns either.
NOCASE=<alternate column name>
In code, this corresponds to the ColumnAttributes property defined at the statement level. Thus, this property is inherited and used by IB_DSQL, IB_Cursor and IB_Query.
It is called ColumnAttributes because it applies to both Params and Fields.
Customizing a Query's Appearance
There are numerous properties for controlling various appearance attributes for a dataset.
You can set field alignment, display format, display width, display label, edit mask, index (order of fields) and visible. All of these attributes are used by the IB_Grid and by the data-aware controls.
These properties affect the appearance of a dataset. Each has its own special set of parameters and follow the same traditional way of having an entry based on the field's name. They are:
Alignment Use "R", "L", or "C" to set a columns alignment. If blank then the default for the column is used.
[<table name>.]<field name>=R
DisplayFormat Use the format for the EditMask on strings and the respective format specifiers for numeric and data-time columns for this property.
[<table name>.]<field name>=mmm/dd/yyyy
DisplayLabel This is used for grid column headings.
[<table name>.]<field name>=Last Name
[<table name>.]<field name>=First Name
DisplayWidth This is used for custom width for grid columns.
[<table name>.]<field name>=150
Index This is used to determine the order of the fields in the Fields array. It is also used by the grid to determine the order of the columns. There are no parameters for these entries. Only the name of the column needs to be entered.
[<table name>.]<field name>
ReadOnly This is used to denote columns that have their values assigned by a trigger or are a COMPUTED column that should not be checked for required data entry.
[<table name>.]<field name>=T
Visible This is used to make a column not show up in a grid.
[<table name>.]<field name>=F
A good way to become familiar with some of these is to move things around in the grid and then go to see how the changes have been received in the FieldsDisplayWidths property. The same holds true for the FieldsIndexProperty.
QBE Edit Fields
InterBase Objects has powerful built-in searching features. When in dssSearch mode the data entry fields become fields to enter in search criteria. These fields go blue when in this mode. To go into dssSearch mode locate the search bar with the book and the cyan question mark over it. Click this button and you will go into search mode. At this point you can type search criteria into the edit fields that are presented to you in the Data tab.
Here is a list of valid QBE search criteria:
· Any valid literal value to serve as a constant. It will be treated as if the "=" operator were used.
· =, !=, <>, >=, <=, <, > are all valid operators that can be applied to literals. For some literals that may contain operator characters it is necessary to put the literal in quotation marks.
· IS NULL or IS NOT NULL are used to search based on the null status of a column.
· When searching strings use of the '%' character acts as a wildcard for 0 to many characters and use of the '_' character acts as a wildcard for a single character. It is like a placeholder. These strings are processed using the LIKE operator.
· BETWEEN <expr1> AND <expr2>
· STARTING [WITH] <expr1>
· IN( <expr1> [, <expr2> ... ] )
· CONTAINING( <expr1> )
Date's are also handled in an interesting fashion. IB dates are in data-time combination so selecting an exact date can be tricky. Mainly because to get an exact match you need to be the same right down to the ten thousandth of a second! When a user enters a date only (ie 01/01/97) in the QBE field it is parsed into a bracketed expression where it is actually seen as:
<col> >= 01/01/97 00:00:000 and <col> <= 01/01/97 23:59:999
This returns all records for that date and ignores the time. Of course, if the user enters any time information then an exact match is sought after.
The special 53 bit integer based numeric columns are properly converted to the right scale and the case insensitive column substitution is properly handled.
To be able to see what statements are generated look in the Monitor tab.